学习新项目时候需要用到es,所以按照教程进行安装,没想到遇到的阻力这么大,还好有写文档的习惯,全过程记录了下来
- 安装配置环境:linux Ubuntu 22.0.4 TLS 新安装的虚拟机一台
- 由于是刚安装的系统,很多环境都没有,本笔记记录的细节非常多,涉及的Error也非常多,个人感觉安装es过程中可能出现的大部分错误都被我遇到了。
- 过程涉及:es安装,环境配置,head插件安装使用,kibana安装使用,IK分词器安装使用,mysql安装使用,logstash安装使用
先解压es安装包,然后运行bin/elastisearch,报错,jdk版本不支持
这是因为es运行需要java支持,有的linux可能没安装java,所以最简单的方法是将es的JAVA_HOME改为jar包里面自带的jdk,然后又报错“openjdk 64-bit server vm warning: option useconcmarksweepgc was deprecated ”,这在之前是个waring,现在直接成了错误了,网上查资料,有的说将jvm.options里面的-XX:+UseConcMarkSweepGC 改为 -XX:+UseG1GC
试了不行,最后终于,知道原来是内存不够,将jvm.options里面的-Xms1g -Xmx1g 修改大小为108m,过后就可以运行了:
## JVM configuration
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms512m-Xmx512m然后又提示不能以root用户运行es,好,先新增一个用户组es和一个用户es,然后改整个文件夹的权限(请注意,一定要使用root用户修改权限,否则权限变动不起作用的)
groupadd es
useradd es -g es
cd /
chown -Rf es:es /root/user/local/lasticsearch/然后su es切换用户
结果切完后发现不对劲:
sh-5.0$
查资料发现是因为默认是shell不是bash,修改/etc/passwd文件,找到用户es,修改后缀sh为bash:

完后切换用户:

切完后因为es用户对当前文件夹没有权限,需要使用root用户打开目标文件夹然后切换用户操作:
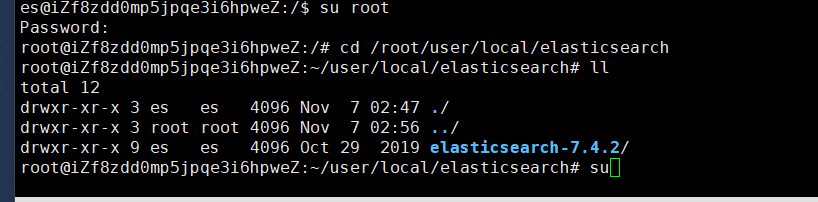
执行bin/elasticsearch命令又出错了,could not find java in JAVA_HOME or bundled at /root/user/local/elasticsearch/elasticsearch-7.4.2/jdk/bin/java
找不到JAVA_HOME
原因是es用户无法执行root下的文件,所以要在/下新加一个文件夹es,然后把es文件夹拷过来,然后切换用户es执行:
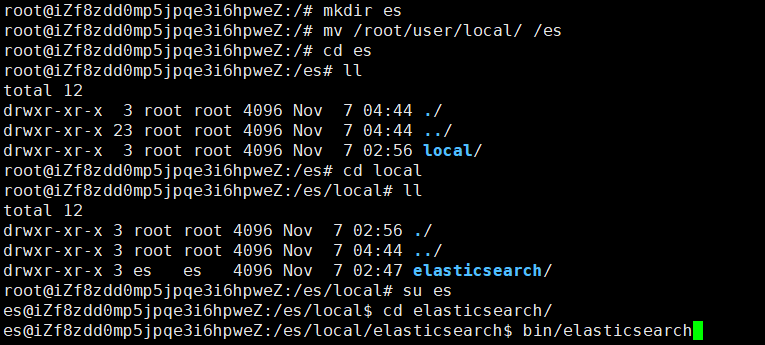
又报错。。。:

原来是因为还没改elasticsearch-env文件:

把java_home路径改好后,启动,终于好了
启动完后正常警告:
[2023-11-07T04:51:53,232][WARN ][o.e.b.BootstrapChecks ] [iZf8zdd0mp5jpqe3i6hpweZ] max number of threads [3478] for user [es] is too low, increase to at least [4096]
[2023-11-07T04:51:53,233][WARN ][o.e.b.BootstrapChecks ] [iZf8zdd0mp5jpqe3i6hpweZ] max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
[2023-11-07T04:51:53,233][WARN ][o.e.b.BootstrapChecks ] [iZf8zdd0mp5jpqe3i6hpweZ] the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured改为后台启动,ctrl+c退出,输入:bin/elasticsearch -d
可以通过curl命令查看是否真正启动:

9200是默认用户服务端口,9300是。。。
启动完成后默认只支持本地访问不能远程访问,需要修改一下允许远程访问

修改这个参数为0.0.0.0:

然后终止当前es进程:
ps -ef|grep elasticsearch
kill -9 pid
然后重新启动,可以看到报错:
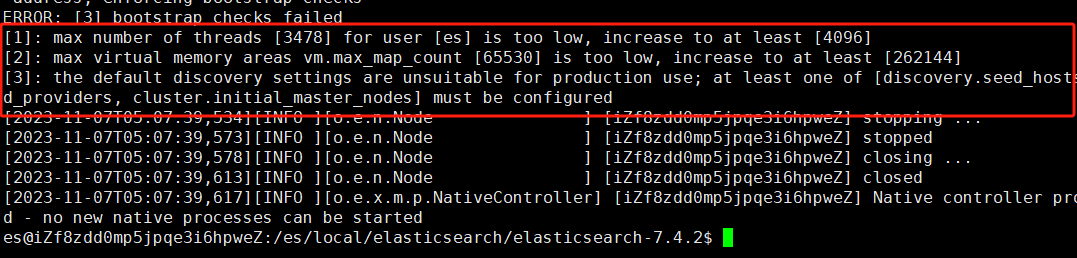
- 错误1:Elasticsearch进程的最大文件描述符[4096]太低,请至少增加到[65535]
- 错误2 :用户[es]可以创建的最大线程数[3795]太低,请至少增加到[4096]
就是前面没有配置这三个
vi /etc/security/limits.conf
追加以下:
es soft nofile 65535
es hard nofile 65535
es soft nproc 4096
es hard nproc 4096 - 错误3:最大虚拟内存区域vm.max_map_count[65530]太低,请至少增加到[262144]
vi /etc/sysctl.conf
在文件末尾添加如下信息
vm.max_map_count = 262144重新加载虚拟内存配置
sysctl -p
- 错误4:当前配置不适合生产环境使用;必须至少配置 [discovery.seed_hosts, discovery.seed_providers,cluster.initial_master_nodes] 之一
- discovery.seed_hosts :集群发现配置,提供集群中符合主机要求的节点的列表. 每个值的格式 为 host:port 或 host ,其中 port 默认为设置 transport.profiles.default.port
- discovery.seed_providers :以文件的方式提供主机列表,可以动态修改,而不用重启节点(容 器化环境适用)
- cluster.initial_master_nodes :指定可以成为 master 的所有节点的 name 或者 ip,这些配置 将会在第一次选举中进行计算
解决:
vi config/elasticsearch.yml
在文件末尾添加如下信息
discovery.seed_hosts: ["127.0.0.1"]
cluster.initial_master_nodes: ["127.0.0.1"] - 解决警告:OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
这是提醒你 CMS 垃圾收集器在 JDK 9 就开始被标注为 @Deprecated ,JDK 11支持的垃圾回收器为 G1 和 ZGC ,而 ZGC 在JDK 11 还处于实验阶段。
修改 config/jvm.options 配置文件
将: -XX:+UseConcMarkSweepGC 改为: -XX:+UseG1GC集群版安装
elasticsearch下新建文件夹es1,解压:
tar -zxvf /root/elasticsearch-7.4.2-linux-x86_64.tar.gz -gz -C /es/local/elasticsearch/es1修改节点名称和端口
复制三个出来
然后修改这三个的权限
chown -Rf es:es /es/local/elasticsearch/
切换用户es,启动两个es
可以使用命令来查看当前节点1是否启动:
curl http://127.0.0.1:9200
然后使用命令查看集群启动情况:
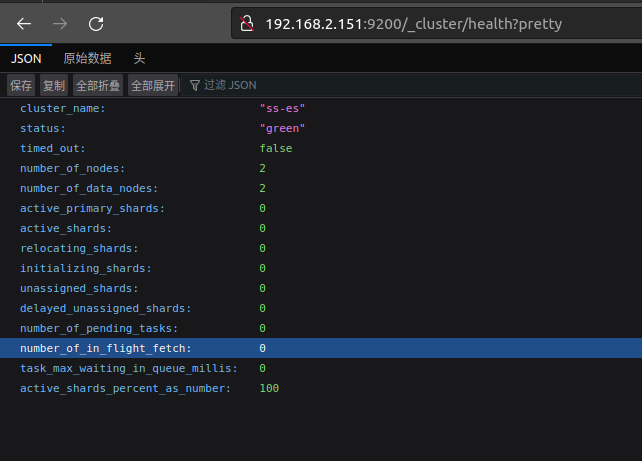
curl http://127.0.0.1:9200/_cluster/health?pretty
结果发现集群节点之间无法相互发现,这个问题又搞了整整一天
到现在还没解决,只能先跳过了,哎
node-1配置:
cluster.name: ss-es
# 集群名,同一个集群,集群名必须一致
node.name: node-1
# 节点名称
network.host: 0.0.0.0
# 节点ip
http.port: 9200
# 节点端口
discovery.seed_hosts: ["192.168.2.151:9300", "192.168.2.151:9301", "192.168.2.192:9302"]
# 集群中节点IP
cluster.initial_master_nodes: ["node-1", "node-2", "node-3"]
# 集群中节点名称
transport.tcp.port: 9300
# es内部通信端口
node.max_local_storage_nodes: 3
# 单节点可以开启ES实例数
http.cors.enabled: true
http.cors.allow-origin: "*"
# 允许建多少索引分片
cluster.max_shards_per_node: 100000
# 集群级别的断路器,默认为jvm堆的70%
indices.breaker.total.limit: 70%
# 单个request的断路器限制,默认为jvm堆的60%
indices.breaker.request.limit: 40%
# fielddata breaker限制,默认为jvm堆的60%
indices.breaker.fielddata.limit: 40%
# 控制字段数据fielddata允许内存大小,达到HEAP 20%自动清理旧cache
indices.fielddata.cache.size: 20%
indices.breaker.total.use_real_memory: false
node-2配置:
cluster.name: ss-es
# 集群名,同一个集群,集群名必须一致
node.name: node-2
# 节点名称
network.host: 0.0.0.0
# 节点ip
http.port: 9201
# 节点端口
discovery.seed_hosts: ["192.168.2.151:9300", "192.168.2.151:9301", "192.168.2.192:9302"]
# 集群中节点IP
cluster.initial_master_nodes: ["node-1", "node-2", "node-3"]
# 集群中节点名称
transport.tcp.port: 9301
# es内部通信端口
node.max_local_storage_nodes: 3
# 单节点可以开启ES实例数
http.cors.enabled: true
http.cors.allow-origin: "*"
# 允许建多少索引分片
cluster.max_shards_per_node: 100000
# 集群级别的断路器,默认为jvm堆的70%
indices.breaker.total.limit: 70%
# 单个request的断路器限制,默认为jvm堆的60%
indices.breaker.request.limit: 40%
# fielddata breaker限制,默认为jvm堆的60%
indices.breaker.fielddata.limit: 40%
# 控制字段数据fielddata允许内存大小,达到HEAP 20%自动清理旧cache
indices.fielddata.cache.size: 20%
indices.breaker.total.use_real_memory: false
报错:
[2023-11-08T14:38:10,227][WARN ][o.e.c.c.ClusterFormationFailureHelper] [node-2] master not discovered yet, this node has not previously joined a bootstrapped (v7+) cluster, and this node must discover master-eligible nodes [node-1, node-2, node-3] to bootstrap a cluster: have discovered [{node-2}{bzeRhfXXSDuG9TYzwCR03g}{dz-RpzwxT1abtAfUEPtRHg}{172.26.12.162}{172.26.12.162:9301}{dilm}{ml.machine_memory=972410880, xpack.installed=true, ml.max_open_jobs=20}, {node-1}{bzeRhfXXSDuG9TYzwCR03g}{Oh9t_tXyRwK4t4DZORxMpg}{172.26.12.162}{172.26.12.162:9300}{dilm}{ml.machine_memory=972410880, ml.max_open_jobs=20, xpack.installed=true}]; discovery will continue using [172.26.12.162:9300, 172.26.12.162:9302] from hosts providers and [{node-2}{bzeRhfXXSDuG9TYzwCR03g}{dz-RpzwxT1abtAfUEPtRHg}{172.26.12.162}{172.26.12.162:9301}{dilm}{ml.machine_memory=972410880, xpack.installed=true, ml.max_open_jobs=20}] from last-known cluster state; node term 0, last-accepted version 0 in term 0
[2023-11-08T14:38:16,733][WARN ][o.e.c.c.ClusterBootstrapService] [node-2] exception when bootstrapping with VotingConfiguration{bzeRhfXXSDuG9TYzwCR03g,{bootstrap-placeholder}-node-3}, rescheduling
org.elasticsearch.cluster.coordination.CoordinationStateRejectedException: not enough nodes discovered to form a quorum in the initial configuration [knownNodes=[{node-2}{bzeRhfXXSDuG9TYzwCR03g}{dz-RpzwxT1abtAfUEPtRHg}{172.26.12.162}{172.26.12.162:9301}{dilm}{ml.machine_memory=972410880, xpack.installed=true, ml.max_open_jobs=20}, {node-1}{bzeRhfXXSDuG9TYzwCR03g}{Oh9t_tXyRwK4t4DZORxMpg}{172.26.12.162}{172.26.12.162:9300}{dilm}{ml.machine_memory=972410880, ml.max_open_jobs=20, xpack.installed=true}], VotingConfiguration{bzeRhfXXSDuG9TYzwCR03g,{bootstrap-placeholder}-node-3}]更新:上面的问题终于解决了,是内存不够用的原因,之前是1g的云服务器,运行完博客系统后剩余内存500mb,估计有些组件无法启动,换linux笔记本,连接同一个wifi,按照上面的配置启动后终于可以访问了:
http://192.168.2.192:9200/_cluster/health?pretty

由于linux系统崩了,现在改用虚拟机,配完上面的步骤之后,启动又报错:
found existing node with the same id but is a different node instance是因为复制es文件夹时将目录下的data也复制了过来,将所有节点的data文件夹内容删掉即可,运行成功: