本笔记参考于 sk 官方文档:
https://github.com/microsoft/semantic-kernel/blob/main/python/notebooks
对SK的认识
个人对于SK的认识1:就是一个通过自然语言+prompt模板调用LLM的工具,可提供的功能有:通过prompt格式化输入输出,对输入数据和输出结果进行二次处理,告诉LLM输入数据是什么样子、应该怎么处理,回答的结果以何种格式(json、向量、亦或数组等)、何种风格返回,自动写入与读取数据库的数据,还有逐步骤多函数处理,这对于复杂内容处理很有用
在SK下,LLM的能力称为 semantic_function ,代码的能力称为 native_function,两者平等的称之为function(功能),一组功能构成一个技能(skill)。 SK的基本能力均是由skill构成。
一个用于简单的完成串行任务的SK程序流程示意图可以概括如下:
暂时无法在飞书文档外展示此内容
所以,一个skill=若干个不同的function相加,那么function是什么呢,其实就是prompt提示词+config文件,只要打开sk源代码,就可以证明:
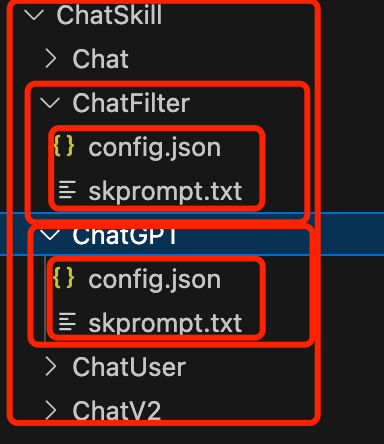
可以看到一个chatskill下有若干个function,每个function由一个skprompt.txt和一个config.json组成
打开chatgpt的prompt看下:
This is a conversation between {{$firstName}} and you.
Your Name: {{$botName}}. Play the persona of: {{$attitude}}.
Use CONTEXT to LEARN ABOUT {{$firstName}}.
[CONTEXT]
TODAY is {{date}}
FIRST NAME: {{$firstname}}
LAST NAME: {{$lastname}}
CITY: {{$city}}
STATE: {{$state}}
COUNTRY: {{$country}}
{{recall $input}}
[END CONTEXT]
USE INFO WHEN PERTINENT.
KEEP IT SECRET THAT YOU WERE GIVEN CONTEXT.
ONLY SPEAK FOR YOURSELF.
{{$firstName}}: I have a question. Can you help?
{{$botName}}: Of course. Go on!
[Done]
{{$history}}
[Done]
++++
{{$firstName}}:{{$input}}
翻译一下:
这是您和{{$firstName}}之间的对话。
您的名字:{{$botName}}。扮演以下角色:{{$attitude}}。
使用背景信息来了解{{$firstName}}。
【背景信息】
今天是{{date}}
名字:{{$firstname}}
姓氏:{{$lastname}}
城市:{{$city}}
州:{{$state}}
国家:{{$country{
"schema": 1,#配置文件版本号
"description": "",
"type": "completion",#文本生成模型
"completion": {#配置电参数
"max_tokens": 150,
"temperature": 0.9,
"top_p": 0.0,
"presence_penalty": 0.6,
"frequency_penalty": 0.0,
"stop_sequences": [
"[Done]"
]
}
}所以从这里可以看出,对于复杂任务,从上到下,首先定义多个技能,然后定义技能需要的函数,对每个函数定义对应的prompt,然后使用planner执行多个skill的计划即可
假设现在要做一个学术”水“论文的AI应用,需求是根据当前论文上下文,去查询国外相关英文论文,找到可用的信息,然后摘录来下,进行清洗,最后翻译成中文,那么可以定义多个skill:
- searchSkill:搜索英文论文
- cleanSkill:查找相关结果,文本清洗
- translateSkill:翻译
将上述三个skill,使用sequenent planner ,规划好这三个skill的使用——按顺序使用,并设置好多个skill的相互参数传递与接受,就可以完成我们的目标了,而且LLM完全会按照给定的方法去完成,而不会胡乱给结果糊弄用户
另外一个想法,就是刚才说的门口的机器人,可以调用其他公司语音识别接口将语音转文字,然后将文本问题输入给gpt,写个skill识别问题的意图,根据意图让LLM自动调用其他的skill
关键词翻译:fine-tuning微调 、text-complection 文本生成
一,helloworld
按照官方文档,helloworld项目非常简单,不需要配置复杂的环境:
- 创建工作目录(我这里文件夹命名SK)
- 从github下载源码放在工作目录下(可以不下载,这里下载是为了方便查阅源码)
- 下载最新的sk包:
python -m pip install –upgrade semantic-kernel
- 新建.env文件,写入:
注:自2023.4.1之后,注册送的$18的api免费调用额度全部过期,所以即便是之前创建的免费3.5的apikey也无法调用会报错,于是从网上暂时花3块钱买了个$5的apikey使用,apikey直接放这里可以直接使用
- 新建hello.py文件
注意.env和hello.py文件同级目录,完整项目目录结构如下:
import semantic_kernel as sk
from semantic_kernel.connectors.ai.open_ai import OpenAIChatCompletion, AzureChatCompletion
ai_model_id="gpt-3.5-turbo"
# ai_model_id="gpt-4"
kernel = sk.Kernel()
# Prepare OpenAI service using credentials stored in the `.env` file
api_key, org_id = sk.openai_settings_from_dot_env()
kernel.add_chat_service("chat-gpt", OpenAIChatCompletion(ai_model_id, api_key, org_id))
prompt = kernel.create_semantic_function("""
用鲁迅的口吻讲一个苏联笑话
""")
# Run prompt
print(prompt()) # =>
输出:
在苏联时期,有一位农民因为种地不得力,被当地的共产党委员会召集到办公室进行批评教育。委员会主席严肃地问道:“你为什么不能像其他农民一样,种出丰收的庄稼呢?”农民低头沉思了一会儿,然后回答道:“主席同志,我想问题可能出在土地上。”
主席听后大怒,指着农民骂道:“你这是什么话?我们的土地是无产阶级的土地,是社会主义的土地,怎么可能有问题?”
农民连忙解释道:“主席同志,我是说土地太大了,我一个人根本无法种完。”
主席听后,顿时笑了起来,他对农民说:“你这个这里可以看到没有输出完整,是因为openai默认有tokens(一个token似乎是一个中文最小语义词汇的意思)的输出限制,可以在create_semantic_function中添加max_tokens参数:
import semantic_kernel as sk
from semantic_kernel.connectors.ai.open_ai import OpenAIChatCompletion, AzureChatCompletion
# ai_model_id="gpt-3.5-turbo"
ai_model_id="gpt-4"
kernel = sk.Kernel()
# Prepare OpenAI service using credentials stored in the `.env` file
api_key, org_id = sk.openai_settings_from_dot_env()
kernel.add_chat_service("chat-gpt", OpenAIChatCompletion(ai_model_id, api_key, org_id))
prompt = kernel.create_semantic_function(
prompt_template="""
用鲁迅的口吻讲一个苏联笑话
""",
max_tokens=4000,#最大为4096 temperature=0.7,
)
# Run prompt
print(prompt()) # => 输出:
在遥远的苏联,有一个关于酒的笑话,让我感到颇为有趣。
故事是这样的,一个苏联公民去市场买酒,但他发现酒架上空空如也,一瓶酒都没有。这个公民十分纳闷,他问商贩:“这是怎么回事,为什么没有酒?”商贩回答说:“你知道吗,有些地方更糟糕,那里连酒架都没有。”
这个笑话虽然简短,但是充斥着讽刺和辛辣的幽默。它展现了在供应短缺的情况下,人们如何以幽默的方式来应对生活的困境。这个笑话并没有直接揭示生活的苦难,却以一种轻松的方式将其暗示出来。这种以笑掩泣的精神,让我想到了我国民众在困难时期的生活状态。
无论是苏联还是我们,都有着面对困难时不屈不挠的精神。虽然生活艰难,但我们都能以乐观的态度应对生活。这是一种来自生活本身的智慧,也是我们生活的动力。关于使用vscode-jupyter扩展工作路径的问题
太坑爹了这个问题,当我将ipynb文件放到SK目录下的二级目录时:
发现获取apikey的openai_settings_from_dot_env函数报错:.env文件未找到
猜测是因为工作路径改变了,但是查看python终端的路径没变,还是SK:
于是使用os模块获取当前工作路径:
import os
# 获取当前工作目录
current_path = os.getcwd()
# 打印当前路径
print("当前工作目录是:", current_path)
发现路径是SK/01-helloworld/
这显然不对,这是由于解释器变了,原本py文件的解释器是python,现在是ipynb文件,解释器换ipynb的解释器了,jupyter扩展默认设置解释器路径为当前ipynb文件的路径,需要修改一下,右键jupyter扩展-扩展设置:
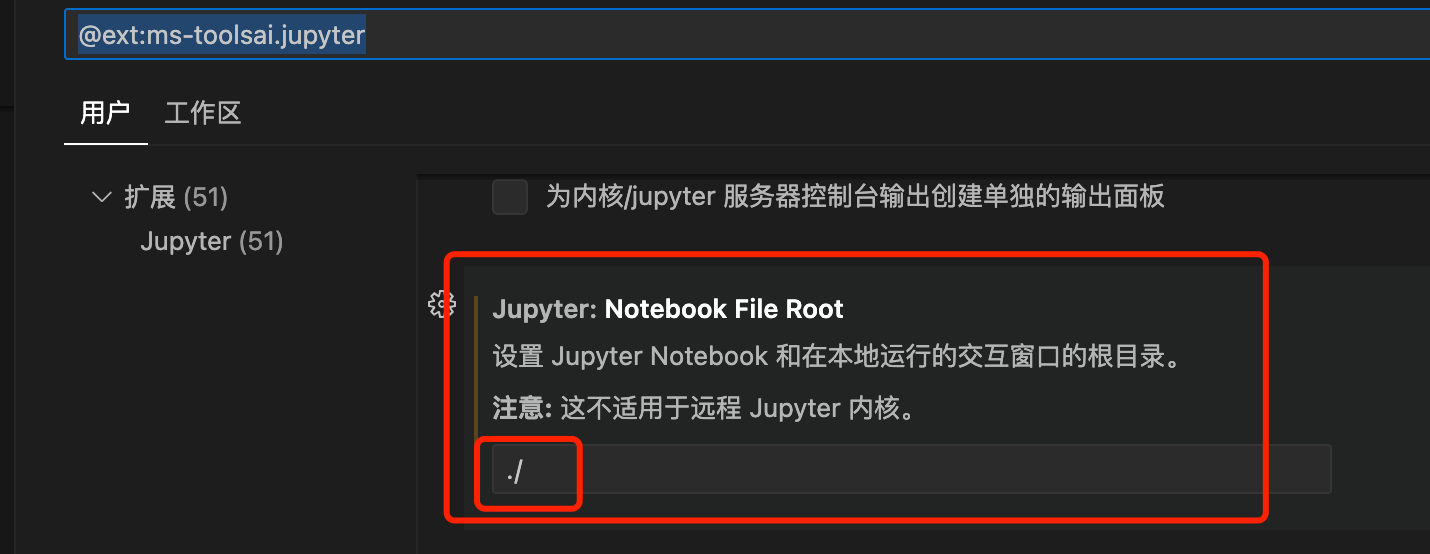
找到这一项,原本值为${fileName},修改为/,表示根目录与python终端路径一致:
然后点击重启内核:
完成
二,语义内核函数, prompt
在Python代码中内联使用语义内核(Semantic Kernel)来定义函数在以下几种情况下非常有用:
- 根据运行时的复杂规则动态生成提示。
- 直接在Python代码中而不是文本文件中编辑提示。
- 轻松创建互动示例,如本文档所示。
语义内核使用一种模板语言,允许引用变量和函数。了解提示模板设计决策的这一特性非常重要。
在初始阶段,本教程主要关注使用{{$input}}变量,这是一种从上下文变量中导入内容的标准方法。文档后面将介绍更复杂的模板。
首先要准备一个语义内核实例,同时还需要加载在设置笔记本中定义的AI服务设置。这一步骤对于将语义内核与现有的Python环境及AI服务整合起来至关重要。
import semantic_kernel as sk
from semantic_kernel.connectors.ai.open_ai import OpenAIChatCompletion
#使用官方的text-davinci-003会报错,提示不再支持这个模型
#更换text-embedding-ada-002后,这个模型似乎特别sb,输出的全是重复的两三个字符
#再次更换,使用gpt-3.5-turbo
kernel = sk.Kernel()
# ai_model_id="gpt-3.5-turbo"
ai_model_id="gpt-4"
api_key, org_id = sk.openai_settings_from_dot_env()
oai_chat_service = OpenAIChatCompletion(ai_model_id=ai_model_id, api_key=api_key, org_id=org_id)
kernel.add_chat_service("chat-gpt", oai_chat_service)使用一个promote来创建一个语义函数,用于概括内容:
sk_prompt = """
{{$input}}
帮我总结一下这段话,使用一句话,不超过30个字
"""
text = """
2022年被称为AIGC元年。2021年之前,AIGC生成主要还是文字,而新一代的模型可以处理的模态大为丰富且支持跨模态产出,可以支持AI插画、文字生成配套视频等常见应用场景。2022年,大量的AI绘画工具涌入市场,以Stable Diffusion为代表的软件纷纷开源,也大大降低了AI作图应用程序的开发门槛,进一步将AI概念推向新的高潮。
在主流的短视频平台、社交平台,逐渐充斥着大量的AI绘画内容,微博的相关话题总阅读数2.2亿,抖音平台中“AI绘画”特效使用近2600万人,对于内容创作者而言,经历了UGC、PGC,如今属于AIGC的时代已经逐渐到来。
"""
tldr_function = kernel.create_semantic_function(prompt_template=sk_prompt, max_tokens=200, temperature=0, top_p=0.5)
summary = tldr_function(text)
print(f"Output: {summary}")
#Output: 2022年是AI绘画元年,AIGC时代已经到来。1,create_semantic_function函数使用
源代码拉出来看看:
def create_semantic_function(
self,
prompt_template: str,
function_name: Optional[str] = None,
skill_name: Optional[str] = None,
description: Optional[str] = None,
**kwargs: Any,
) -> "SKFunctionBase":
function_name = function_name if function_name is not None else f"f_{str(uuid4()).replace('-', '_')}"
config = PromptTemplateConfig(
description=(description if description is not None else "Generic function, unknown purpose"),
type="completion",
completion=AIRequestSettings(extension_data=kwargs),
)
validate_function_name(function_name)
if skill_name is not None:
validate_skill_name(skill_name)
template = PromptTemplate(prompt_template, self.prompt_template_engine, config)
function_config = SemanticFunctionConfig(config, template)
return self.register_semantic_function(skill_name, function_name, function_config)
create_semantic_function接受一定的参数,并返回一个SK函数,prompt_template字符串必填,其他参数可选
最佳实践使用方式:
AnswerFunction = kernel.create_semantic_function( prompt_template=sk_prompt, function_name="answerFunction", skill_name="MyAnswerSkill", max_tokens=3000, temperature=0.8, description="回答用户奇怪的问题" )2,prompt优化,格式化输出
import os
# 获取当前文件的绝对路径
current_dir = os.path.dirname(os.path.abspath(__file__))
# 将当前文件的路径设置为工作路径
os.chdir(current_dir)
async def main():
import semantic_kernel as sk
import config.add_completion_service
# Initialize the kernel
kernel = sk.Kernel()
# Add a text or chat completion service using either:
# kernel.add_text_completion_service()
# kernel.add_chat_service()
kernel.add_completion_service()
# request = input("Your request: ")
request="什么是LLM大模型?"
# 0.0 Initial prompt
prompt = f"Instructions:这个提问的意图是什么? {request}"
print("--------------0.0 最简单的提示词")
semantic_function = kernel.create_semantic_function(prompt)
print(await kernel.run_async(semantic_function))
# 这里我们希望只需要三个字:问问题,但是IA啰嗦呀大队,下面解决这个问题
# 1.0 Make the prompt more specific
prompt = f"""Instructions:这个提问的意图是什么? {request}
你可以从以下选项中选择: 发邮件, 发短信, 问问题, 写代码."""
print("--------------1.0 让提示更加具体")
semantic_function = kernel.create_semantic_function(prompt)
print(await kernel.run_async(semantic_function))
# 2.0 Add structure to the output with formatting
prompt = f"""Instructions: 下面用户输入的这个提问的意图是什么?
选项: 发邮件, 发短信, 问问题, 写代码
用户输入: {request}
意图: """
print("--------------2.0 格式化输出")
semantic_function = kernel.create_semantic_function(prompt)
print(await kernel.run_async(semantic_function))
# 2.1 Add structure to the output with formatting (using Markdown and JSON)
prompt = f"""## Instructions
通过下面的格式告诉我这个问题的意图:{request}
```json
{{
"intent": {{intent}}
}}
```
## Choices
你可以从下面几个选项中选择:
```json
["发邮件", "发短信", "问问题", "写代码"]
```
## User Input
用户输入的是:
```json
{{
"request": "{request}"\n'
}}
```
## Intent"""
print("2.1 让AI进行标准格式化输出,比如json格式")
semantic_function = kernel.create_semantic_function(prompt)
print(await kernel.run_async(semantic_function))
# 3.0 Provide examples with few-shot prompting
prompt = f"""Instructions: 这个提问的意图是什么?{request}
选择: 发邮件, 发短信, 问问题, 写代码
用户输入: 你能明天早上短信通知我带雨伞吗
意图: 发短信
用户输入: 你能把这个行程单发我邮箱吗
意图: 发邮件
用户输入: {request}
意图: """
print("3.0 给AI提供一些输出格式的样例")
semantic_function = kernel.create_semantic_function(prompt)
print(await kernel.run_async(semantic_function))
# 4.0 Tell the AI what to do to avoid doing something wrong
prompt = f"""Instructions: 这个提问的意图是什么?{request}
如果你不知道答案,请不要乱猜,直接说Unknown即可
选择: 发邮件, 发短信, 问问题, 写代码, Unknown.
用户输入: 你能明天早上短信通知我带雨伞吗
意图: 发短信
用户输入: 你能把这个行程单发我邮箱吗
意图: 发邮件
用户输入: {request}
意图: """
print("--------------4.0 告诉AI如何避免犯错")
semantic_function = kernel.create_semantic_function(prompt)
print(await kernel.run_async(semantic_function))
# 5.0 Provide context to the AI
history = (
"用户输入: 我讨厌邮件,没人愿意读那玩意.\n"
"AI回答: 很抱歉,你还是用短息吧"
)
prompt = f"""Instructions: 这个提问的意图是什么?{request}"
如果你不知道答案,请不要乱猜,直接说Unknown即可
选择: 发邮件, 发短信, 问问题, 写代码, Unknown.
用户输入: 你能明天早上短信通知我带雨伞吗
意图: 发短信
用户输入: 你能把这个行程单发我邮箱吗
意图: 发邮件
{history}
用户输入: {request}
意图: """
print("--------------5.0 提供上下文给AI")
semantic_function = kernel.create_semantic_function(prompt)
print(await kernel.run_async(semantic_function))
# Run the main function
if __name__ == "__main__":
import asyncio
asyncio.run(main())
输出:
--------------0.0 最简单的提示词
这个提问的意图是询问LLM大模型的定义和解释。
LLM大模型是指"Language Learning Model"(语言学习模型)的缩写。它是一种用于自然语言处理(NLP)任务的深度学习模型。LLM大模型通常由多个神经网络层组成,可以用于诸如机器翻译、文本生成、情感分析等任务。这些模型通过学习大量的语言数据,能够理解和生成自然语言文本。LLM大模型的训练通常需要大量的计算资源和数据集,例如GPT-3(Generative Pre-trained Transformer 3)就是一种著名的LLM大模型。
--------------1.0 让提示更加具体
这个提问的意图是询问LLM大模型的定义和解释。
--------------2.0 格式化输出
问问题
2.1 让AI进行标准格式化输出,比如json格式
{
"intent": "问问题"
}
3.0 给AI提供一些输出格式的样例
问问题
--------------4.0 告诉AI如何避免犯错
问问题
--------------5.0 提供上下文给AI
问问题3,为sk函数传入变量
之前,我们写prompt的时候:
request="什么是LLM大模型?"
prompt = f"Instructions:这个提问的意图是什么? {request}"request都是直接在代码里定义死了,实际开发这个变量肯定要传进去,sk设置变量很简单,直接设置在kernel中:variables = sk.ContextVariables(),然后通过variables[“name”] = value设置即可
下面我们定义一个求两个数平方和的prompt,然后每次动态传入参数来调用:
import os
# 获取当前文件的绝对路径
current_dir = os.path.dirname(os.path.abspath(__file__))
# 将当前文件的路径设置为工作路径
os.chdir(current_dir)
async def main():
import semantic_kernel as sk
import config.add_completion_service
# Initialize the kernel
kernel = sk.Kernel()
# Add a text or chat completion service using either:
# kernel.add_text_completion_service()
# kernel.add_chat_service()
kernel.add_completion_service()
# Create the history
history = ["对话开始"]
prompt = """
接下来,你是一个完成平方差的函数,每次对话我都会输入两个数a和b,你只需要告诉我(a+b)^2是多少就行,计算的值result以下面的json格式返回:
{
”result“:result
}
{{$history}}
用户输入:: a={{$a}},b={{$b}}
输出:
"""
while True:
a = input("a= > ")
b = input("a= > ")
variables = sk.ContextVariables()
variables["a"] = a
variables["b"] = b
variables["history"] = "\n".join(history)
# Run the prompt
semantic_function = kernel.create_semantic_function(prompt)
result = await kernel.run_async(
semantic_function,
input_vars=variables,
)
# Add the request to the history
history.append("用户输入: " + a+","+b)
history.append("输出" + result.result)
print("AI输出 > \n" + result.result)
# Run the main function
if __name__ == "__main__":
import asyncio
asyncio.run(main())
输出:
a= > 3
a= > 4
AI输出 >
{
"result": 49
}
a= > 1 2
a= > 3
AI输出 >
{
"result": 25
}
a= > 1
a= > 2
AI输出 >
{
"result": 9
}可以看到,成功实现了功能
4,定义自己的prompt
下面演示如何定义自己的skprompt.txt和config.json,并且进行调用
在当前py文件同级目录创建文件夹:

写入config:
{
"schema": 1,
"type": "completion",
"description": "计算完全平方和",
"completion": {
"max_tokens": 200,
"temperature": 0.5,
"top_p": 0.0,
"presence_penalty": 0.0,
"frequency_penalty": 0.0
},
"input": {
"parameters": [
{
"name": "a",
"description": "value a",
"defaultValue": "0"
},
{
"name": "b",
"description": "value b",
"defaultValue": "0"
}
]
}
}
写入skprompt.txt:
接下来,你是一个完成平方差的函数,每次对话我都会输入两个数a和b,你只需要告诉我(a+b)^2是多少就行,计算的值result以下面的json格式返回:
{
”result“:result
}
{{$history}}
用户输入: a={{$a}},b={{$b}}
输出:
调用:
import os
# 获取当前文件的绝对路径
current_dir = os.path.dirname(os.path.abspath(__file__))
# 将当前文件的路径设置为工作路径
os.chdir(current_dir)
async def main():
import semantic_kernel as sk
import config.add_completion_service
# Initialize the kernel
kernel = sk.Kernel()
# Add a text or chat completion service using either:
# kernel.add_text_completion_service()
# kernel.add_chat_service()
kernel.add_completion_service()
context = kernel.create_new_context()
context["history"] = "对话开始\n"
plugins_directory = "myPlugins"
MathPlugin = kernel.import_semantic_skill_from_directory(
plugins_directory, "MathPlugin"
)
while True:
a = input("a= > ")
b = input("a= > ")
context["a"] = a
context["b"] = b
context["history"]+="\n用户输入:"+a+","+b+"\n"
# Run the prompt
# semantic_function = kernel.create_semantic_function(prompt)
result = await kernel.run_async(
MathPlugin["SumOfPerfectSquares"],input_context=context
)
# Add the request to the history
context["history"]+="\n输出" + result.result
print("AI输出 > \n" + result.result)
# Run the main function
if __name__ == "__main__":
import asyncio
asyncio.run(main())
输出:
a= > 3
a= > 4
AI输出 >
{
"result": 49
}成功
5,GPT翻译插件的实现
下面,我来动手写个实用的插件——翻译插件
0.1版本需求很简单:输入文本,给出中文到英文的翻译结果即可
首先定义一个插件plugin:
config.json如下:
{
"schema": 1,
"type": "completion",
"description": "基本英到中的翻译",
"completion": {
"max_tokens": 3000,
"temperature": 0.5,
"top_p": 0.0,
"presence_penalty": 0.0,
"frequency_penalty": 0.0
},
"input": {
"parameters": [
{
"name": "inputSentence",
"description": "value a",
"defaultValue": "0"
}
]
}
}
skprompt.txt内容如下:
接下来,你将扮演一个随身翻译的角色,我会告诉你要翻译的文本inputSentence,使用尽量中文本土风格翻译成中文给我,
对于不确定什么意思的单词,或者你怀疑是专有名词的一些单词,比如“SK”,
或者下划线连接的单词比如“frequency_penalty”等,这种单词不需要翻译,
另外,你还可以根据之前的翻译记录来参考上下文进行更高质量的翻译
最后将翻译的结果以下面的json格式返回:
{
”result“:翻译结果
}
{{$history}}
用户输入: inputSentence={{$inputSentence}}
输出:
目录如下:
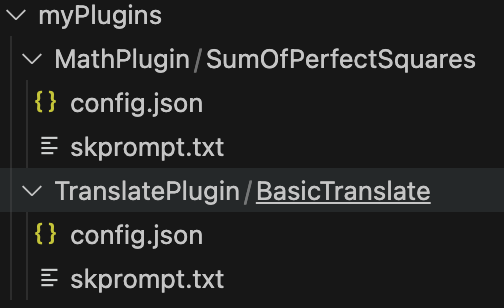
编写代码:
import os
# 获取当前文件的绝对路径
current_dir = os.path.dirname(os.path.abspath(__file__))
# 将当前文件的路径设置为工作路径
os.chdir(current_dir)
async def main():
import semantic_kernel as sk
import config.add_completion_service
# Initialize the kernel
kernel = sk.Kernel()
# Add a text or chat completion service using either:
# kernel.add_text_completion_service()
# kernel.add_chat_service()
kernel.add_completion_service()
context = kernel.create_new_context()
context["history"] = "对话开始\n"
plugins_directory = "myPlugins"
MathPlugin = kernel.import_semantic_skill_from_directory(
plugins_directory, "TranslatePlugin"
)
while True:
inputSentence = input("inputSentence= > ")
context["inputSentence"] = inputSentence
context["history"]+="\n用户输入:"+inputSentence+"\n"
result = await kernel.run_async(
MathPlugin["BasicTranslate"],input_context=context
)
# Add the request to the history
context["history"]+="\n输出" + result.result
print("AI输出 > \n" + result.result)
# Run the main function
if __name__ == "__main__":
import asyncio
asyncio.run(main())
测试:
inputSentence= > hello world
AI输出 >
{
"result": "你好世界"
}
inputSentence= > Add a text or chat completion service using either
AI输出 >
{
"result": "使用任何一种方式添加一个文本或聊天完成服务"
}
inputSentence= > 如果需要做浏览器翻译插件,只需要写好前端,后端将这个服务启动对外监听端口,接受请求处理返回即可
如果需要增加参数,比如用户可以选择英翻中还是中译英,直接在请求中添加参数,后端run_async时候选择不同的function即可,实现如下:
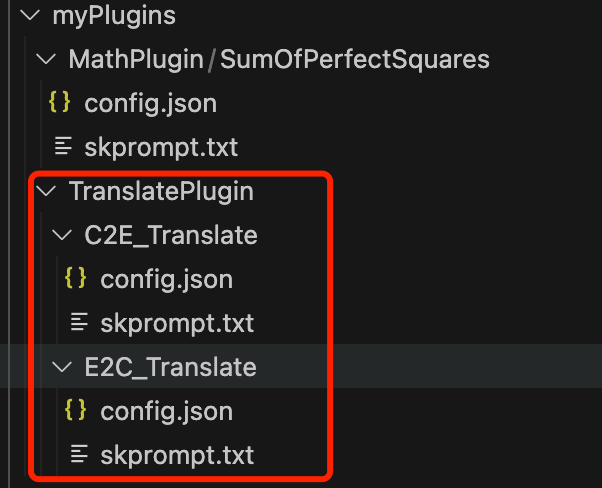
import os
# 获取当前文件的绝对路径
current_dir = os.path.dirname(os.path.abspath(__file__))
# 将当前文件的路径设置为工作路径
os.chdir(current_dir)
async def main():
import semantic_kernel as sk
import config.add_completion_service
# Initialize the kernel
kernel = sk.Kernel()
# Add a text or chat completion service using either:
# kernel.add_text_completion_service()
# kernel.add_chat_service()
kernel.add_completion_service()
context = kernel.create_new_context()
context["history"] = "对话开始\n"
plugins_directory = "myPlugins"
MathPlugin = kernel.import_semantic_skill_from_directory(
plugins_directory, "TranslatePlugin"
)
option=input("请选择翻译模式,1为英文到中文,2为中文到英文> ")
if int(option)==1:
while True:
inputSentence = input("输入英文文本 > ")
context["inputSentence"] = inputSentence
context["history"]+="\n用户输入:"+inputSentence+"\n"
result = await kernel.run_async(
MathPlugin["E2C_Translate"],input_context=context
)
# Add the request to the history
context["history"]+="\n输出" + result.result
print("翻译结果 > \n" + result.result)
else:
while True:
inputSentence = input("输入中文文本 > ")
context["inputSentence"] = inputSentence
context["history"]+="\n用户输入:"+inputSentence+"\n"
result = await kernel.run_async(
MathPlugin["C2E_Translate"],input_context=context
)
# Add the request to the history
context["history"]+="\n输出" + result.result
print("翻译结果 > \n" + result.result)
# Run the main function
if __name__ == "__main__":
import asyncio
asyncio.run(main())
请选择翻译模式,1为英文到中文,2为中文到英文> 2
输入中文文本 > 你好世界
翻译结果 >
{
"result": "Hello world"
}
输入中文文本 > 在SK下,LLM的能力称为 semantic_function ,代码的能力称为 native_function,两者平等的称之为function(功能),一组功能构成一个技能(skill)。 SK的基本能力均是由skill构成。
翻译结果 >
{
"result": "In SK, the ability of LLM is called semantic_function, and the ability of code is called native_function. Both are referred to as function. A group of functions constitutes a skill. The basic abilities of SK are all composed of skills."
}
输入中文文本 >
三,让LLM记住对话历史
上面的使用变量存储对话信息的方式有很繁琐,下面介绍另一种存储对话记录的方法——使用context来存储上下文信息来进行完整的AI对话,这种方式的特点是变量可以存储在context中
import os
# 获取当前文件的绝对路径
current_dir = os.path.dirname(os.path.abspath(__file__))
# 将当前文件的路径设置为工作路径
os.chdir(current_dir)
async def main():
import semantic_kernel as sk
import config.add_completion_service
# Initialize the kernel
kernel = sk.Kernel()
# Add a text or chat completion service using either:
# kernel.add_text_completion_service()
# kernel.add_chat_service()
kernel.add_completion_service()
context = kernel.create_new_context()
context["history"] = "对话开始\n"
prompt = """
接下来,你是一个完成平方差的函数,每次对话我都会输入两个数a和b,你只需要告诉我(a+b)^2是多少就行,计算的值result以下面的json格式返回:
{
”result“:result
}
{{$history}}
用户输入: a={{$a}},b={{$b}}
输出:
"""
while True:
a = input("a= > ")
b = input("a= > ")
context["a"] = a
context["b"] = b
context["history"]+="\n用户输入:"+a+","+b+"\n"
# Run the prompt
# semantic_function = kernel.create_semantic_function(prompt)
semantic_function = kernel.create_semantic_function(
prompt_template=prompt,
function_name="Sum_of_Perfect_Squares_FuncBot",
max_tokens=3000,
temperature=0.7,
)
result = await semantic_function.invoke_async(context=context)
# Add the request to the history
context["history"]+="\n输出" + result.result
print("AI输出 > \n" + result.result)
# Run the main function
if __name__ == "__main__":
import asyncio
asyncio.run(main())
四,Planner
planner是语义内核的基本概念之一。它利用已注册到内核的本机和语义函数的集合,并使用人工智能,将制定执行给定请求的计划。
我们可以提前准备好所需的Skill,根据设定好的最终目标,通过Planner,可以将目标分解为需要执行的任务列表,并且可以指定好对应的参数传递,然后逐个任务执行,从而实现最终目标。
#常规引包、创建kernel
import semantic_kernel as sk
from semantic_kernel.connectors.ai.open_ai import OpenAIChatCompletion
ai_model_id="gpt-3.5-turbo"
# ai_model_id="gpt-4"
kernel = sk.Kernel()
api_key, org_id = sk.openai_settings_from_dot_env()
oai_chat_service = OpenAIChatCompletion(ai_model_id=ai_model_id, api_key=api_key, org_id=org_id)
kernel.add_chat_service("chat-gpt", oai_chat_service)planner需要知道自己可以使用哪些技能。在这里,我们将授予它访问我们在磁盘上定义的SummarizeSkill 和 WriterSkill的权限。这将包括许多语义函数,planner将智能地选择其中的子集(也就是智能得选择使用哪个技能,比如总结还是写作)
from semantic_kernel.core_skills.text_skill import TextSkill
skills_directory = "semantic-kernel/samples/skills/"
summarize_skill = kernel.import_semantic_skill_from_directory(skills_directory, "SummarizeSkill")
writer_skill = kernel.import_semantic_skill_from_directory(skills_directory, "WriterSkill")
text_skill = kernel.import_skill(TextSkill(), "TextSkill")
chat_Skill=kernel.import_skill(skills_directory,"ChatSkill")这里的skill其实就是[配置参数+prompt],可以打开semantic-kernel/samples/skills/查看,就是一个skprompt.txt(prompt)+config.json(配置参数)
from semantic_kernel.core_skills.text_skill import TextSkill
skills_directory = "semantic-kernel/samples/skills/"
kernel.import_semantic_skill_from_directory(skills_directory, "SummarizeSkill")
kernel.import_semantic_skill_from_directory(skills_directory, "WriterSkill")
kernel.import_skill(TextSkill(), "TextSkill")
kernel.import_semantic_skill_from_directory(skills_directory,"ChatSkill")
kernel.import_semantic_skill_from_directory(skills_directory,"CodingSkill")1,BasicPlanner
(basic planner其实不重要)
basic planner按顺序解决问题,首先拿到问题后进行问题分解得到若干个子问题,接着按顺序执行解决这几个子问题:
PlannerRole="basic"
match PlannerRole:
case "basic":
from semantic_kernel.planning.basic_planner import BasicPlanner
planner = BasicPlanner()
#其实这里定义的AnswerFunction和上面导入的kernel.import_semantic_skill_from_directory(skills_directory, "SummarizeSkill")的SummarizeSkill作用一模一样
#都是给定一个prompt,然后定义参数
ask = """
n=5,请计算n的阶乘是多少,使用python
计算完成后,将结果乘以20返回给我
"""
new_plan = await planner.create_plan_async(ask, kernel)
print(new_plan.generated_plan)
#执行
results = await planner.execute_plan_async(new_plan, kernel)
print(results)
输出:
{
"input": "5",
"subtasks": [
{"function": "CodingSkill.CodePython", "args": {"input": "factorial(5)"}},
{"function": "CodingSkill.CodePython", "args": {"input": "result * 20"}}
]
}
# Start
# Function to print all strings in a list
def appendprefix(values):
for val in values: # iterate through each value in the list
print(val) # print the value
# Done
#result * 20
# Test the function
values = ["result"] * 20 # create a list with "result" repeated 20 times
appendprefix(values) # call the function with the list as input
print("done") # print "done" to indicate that the code execution is complete可以看到将我的任务分解为两个步骤:先计算阶乘,然后将结果乘以20并返回
注:如果使用了自定义function,那么可能只会分解为一个自定义的子任务:
PlannerRole="basic"
match PlannerRole:
case "basic":
from semantic_kernel.planning.basic_planner import BasicPlanner
planner = BasicPlanner()
sk_prompt = """
{{$input}}
分别使用中文和英文回答我的这个问题,英文所有字母都要大写,中文每20字左右一行
"""
#这个create_semantic_function函数是在kernel内部注册一个函数,并把这个函数句柄返回,不需要外部显式调用
AnswerFunction = kernel.create_semantic_function( prompt_template=sk_prompt, function_name="answerFunction", skill_name="MyAnswerSkill", max_tokens=4000, temperature=0.8, description="回答用户奇怪的问题" )
#其实这里定义的AnswerFunction和上面导入的kernel.import_semantic_skill_from_directory(skills_directory, "SummarizeSkill")的SummarizeSkill作用一模一样
#都是给定一个prompt,然后定义参数
ask = """
如何使用意大利面和42号混凝土来实现达利园效应
"""
new_plan = await planner.create_plan_async(ask, kernel)
print(new_plan.generated_plan)
#执行
results = await planner.execute_plan_async(new_plan, kernel)
print(results)
输出:
{
"input": "如何使用意大利面和42号混凝土来实现达利园效应",
"subtasks": [
{"function": "MyAnswerSkill.answerFunction"}#只分解为一个自定义子任务
]
}
中文回答:
使用意大利面和42号混凝土来实现达利园效应需要以下步骤:
1. 准备材料:购买意大利面和42号混凝土。
2. 将42号混凝土按照包装上的指示用水搅拌均匀,确保混凝土具有适当的流动性。
3. 在一个平坦的表面上铺设塑料薄膜,以防止混凝土黏附在表面上。
4. 将混凝土倒入模具中,模具可以是任意形状,如圆形、方形或自定义形状。
5. 在混凝土表面均匀地撒上意大利面,可以选择不同形状和大小的意大利面,以增加艺术效果。
6. 轻轻按压意大利面,使其陷入混凝土中,但不要压得太深。
7. 等待混凝土干燥和凝固,时间根据混凝土厚度和环境条件而定,一般需要几天到几周。
8. 小心地将混凝土从模具中取出,并轻轻清除多余的意大利面。
9. 您现在可以欣赏到意大利面和混凝土的达利园效应了!
English answer:
To achieve the Dali garden effect using spaghetti and concrete mix 42, follow these steps:
1. Prepare the materials: purchase spaghetti and concrete mix 42.
2. Mix the concrete mix 42 with water according to the instructions on the package, ensuring that the concrete has the right consistency.
3. Lay a plastic sheet on a flat surface to prevent the concrete from sticking to the surface.
4. Pour the concrete into a mold, which can be of any shape such as circular, square, or custom.
5. Sprinkle spaghetti evenly on the surface of the concrete. You can choose different shapes and sizes of spaghetti to enhance the artistic effect.
6. Gently press the spaghetti into the concrete, but not too deep.
7. Wait for the concrete to dry and solidify. The time needed will depend on the thickness of the concrete and environmental conditions, usually ranging from a few days to a few weeks.
8. Carefully remove the concrete from the mold and gently remove any excess spaghetti.
9. Now you can enjoy the Dali garden effect created by spaghetti and concrete!补充
这里有个疑问,为什么要使用kernel.import_semantic_skill_from_directory逐个引入skill?
其实,如果把上面的四个skill注释掉,也就是不引入skill,而且下面kernel.create_semantic_function也注释掉,运行,会发现没有结果:
Variable $available_functions not found
Variable $goal not found
{
"input": "老鼠生病了该吃老鼠药吗",
"subtasks": [
{"function": "_GLOBAL_FUNCTIONS_.f_bb9338a6_26bd_478f_aded_e63de7e224a2", "args": {"available_functions": [], "goal": ""}}
]
}
{
"input": "",
"subtasks": []
}这是因为这个kernel没有任何的技能可供选择,当调用new_plan.generated_plan时,kernel会从skill列表中选择对应skill使用,但是根本就没有,所以当然是无子任务,也无输出
如果仅仅引入了某个skill比如CodingSkill,但是问的问题不是代码类型的问题,可能会得不到结果:
kernel.import_semantic_skill_from_directory(skills_directory,"CodingSkill")
PlannerRole="basic"
match PlannerRole:
case "basic":
from semantic_kernel.planning.basic_planner import BasicPlanner
planner = BasicPlanner()
sk_prompt = """
{{$input}}
回答我的问题
"""
#这个create_semantic_function函数是在kernel内部注册一个函数,并把这个函数句柄返回,不需要外部显式调用
# AnswerFunction = kernel.create_semantic_function(
# prompt_template=sk_prompt,
# function_name="answerFunction",
# skill_name="AnswerFunction",
# max_tokens=4000,
# temperature=0.8,
# description="回答用户奇怪的问题"
# )
#其实这里定义的AnswerFunction和上面导入的kernel.import_semantic_skill_from_directory(skills_directory, "SummarizeSkill")的SummarizeSkill作用一模一样
#都是给定一个prompt,然后定义参数
ask = """
如何使用意大利面和42号混凝土来实现达利园效应
"""
new_plan = await planner.create_plan_async(ask, kernel)
print(new_plan.generated_plan)
#执行
results = await planner.execute_plan_async(new_plan, kernel)
print(results)输出:
{
"input": "如何使用意大利面和42号混凝土来实现达利园效应",
"subtasks": [
{"function": "CodingSkill.Entity", "args": {"tags": ["food", "material"], "input": "意大利面和42号混凝土"}},
{"function": "CodingSkill.Code", "args": {"input": "达利园效应"}}
]
}
I would like to generate code that explains the Dunning-Kruger effect in natural language. The code should be written in Python.就相当于你给LLM提了这个问题:
请帮我基于以下需求完成代码实现:
——如何使用意大利面和42号混凝土来实现达利园效应这根本不是一个正常人能提出来的问题,当然没有结果
个人理解使用kernel.import_semantic_skill_from_directory逐个引入skill的优点是可以精准使用skill(或者说prompt),而不会出现让LLM回答问题,但是LLM给你的回答是总结问题这样的情况
如果需要开发一个专业定向能力很强的LLM,可以使用create_semantic_function自定义一个skill,然后不要import任何其他的skill
此外,还有个很重要的优点就是,你可以自定义一些列的function,然后逐步顺序组成一个plan,指定好对应的参数传递,然后逐个任务执行,从而实现最终目标。
2,Action Planner
行为planner吸收一系列的函数动作和目标,然后输出一个适合某个目标的单一plan,最后执行这个plan即可
相比于其他的planner,action planner就是生成特定plan的作用,比如,要做一个法律小助手,个人猜测是先导入一系列的技能+ask生成一个用于法律咨询的plan,然后执行这个plan
#常规引包、创建kernel
import semantic_kernel as sk
from semantic_kernel.connectors.ai.open_ai import OpenAIChatCompletion
ai_model_id="gpt-3.5-turbo"
# ai_model_id="gpt-4"
kernel = sk.Kernel()
api_key, org_id = sk.openai_settings_from_dot_env()
oai_chat_service = OpenAIChatCompletion(ai_model_id=ai_model_id, api_key=api_key, org_id=org_id)
kernel.add_chat_service("chat-gpt", oai_chat_service)
from semantic_kernel.planning import ActionPlanner
planner = ActionPlanner(kernel)
#添加技能
from semantic_kernel.core_skills import FileIOSkill, MathSkill, TextSkill, TimeSkill
kernel.import_skill(MathSkill(), "math")
kernel.import_skill(FileIOSkill(), "fileIO")
kernel.import_skill(TimeSkill(), "time")
kernel.import_skill(TextSkill(), "text")
ask = "What is the sum of 110 and 990?"
#根据目标生成一个plan
plan = await planner.create_plan_async(goal=ask)
#根据plan去solve问题
result = await plan.invoke_async()
print(result)五,让LLM记住对话历史——进阶
1,构建嵌入式的语义记忆
之前第三节(让LLM记住对话历史)中我们使用history来记录历史上下文信息,然而这种方式随着对话次数的增多,上下文历史信息会逐渐庞大,会逐渐超过模型的记忆限制。需要一种新的方法来持久化状态,并构建短期和长期记忆
这就涉及到了“Semantic Memory”语义记忆
为了保存记忆,我们需要通过嵌入式服务和记忆存储器来初始化一个kernel
在这个示例中,我们使用一个可以被当做短时记忆存储的 VolatileMemoryStore,这个内存生命周期是app会话期(启动初始化,结束被回收),是不会被写到磁盘上
实际开发app时,可以选择数据持久化存储策略,如PostgreSQL、SQLite等。另外语义记忆还允许索引外部数据源
from typing import Tuple
import semantic_kernel as sk
from semantic_kernel.connectors.ai.open_ai import (
OpenAIChatCompletion,
OpenAITextEmbedding,
)
kernel = sk.Kernel()
api_key, org_id = sk.openai_settings_from_dot_env()
oai_chat_service = OpenAIChatCompletion(ai_model_id="gpt-3.5-turbo", api_key=api_key, org_id=org_id)
oai_text_embedding = OpenAITextEmbedding(ai_model_id="text-embedding-ada-002", api_key=api_key, org_id=org_id)
kernel.add_chat_service("chat-gpt", oai_chat_service)
kernel.add_text_embedding_generation_service("ada", oai_text_embedding)
kernel.register_memory_store(memory_store=sk.memory.VolatileMemoryStore())
kernel.import_skill(sk.core_skills.TextMemorySkill())在这个kernel中,记忆是一段允许你存储来自于之前输入的各种数据源的文本意思信息,这段文本信息可以来自于网络、email、对话、数据库、或者本地文件,通过数据源连接器与kernel相连
另外,这些文本数据不是直接通过txt存储的,而是通过数字化的向量来存储
接下来演示如何增加我们的角色信息到LLM的记忆,可以通过SaveInformationAsync来增加记忆到VolatileMemoryStore中去:
async def populate_memory(kernel: sk.Kernel) -> None:
# 编写填充/写入记忆的函数
await kernel.memory.save_information_async(collection="aboutMe", id="info1", text="我叫丁真")
await kernel.memory.save_information_async(collection="aboutMe", id="info2", text="我是一个抽象艺术家")
await kernel.memory.save_information_async(collection="aboutMe", id="info3", text="我从2000年就生活在理塘")
await kernel.memory.save_information_async(collection="aboutMe", id="info4", text="从2015年起我每天抽电子烟",)
await kernel.memory.save_information_async(collection="aboutMe", id="info5", text="我家在理塘")千万别忘了调用该函数写入记忆!
await populate_memory(kernel)好了,现在开始问他问题,看他到底有没有记住我的信息:
async def search_memory_examples(kernel: sk.Kernel) -> None:
questions = [
"我叫什么",
"我住在哪里?",
"我家来自哪里?",
"我去过哪里?",
"我曾经做过什么",
]
for question in questions:
print(f"Question: {question}")
result = await kernel.memory.search_async("aboutMe", question)
print(f"Answer: {result[0].text}\n")
await search_memory_examples(kernel)
#输出:
# Question: 我叫什么
# Answer: 我叫丁真
# Question: 我住在哪里?
# Answer: 我家在理塘
# Question: 我家来自哪里?
# Answer: 我家在理塘
# Question: 我去过哪里?
# Answer: 我从2000年就生活在理塘
# Question: 我曾经做过什么
# Answer: 我是一个抽象艺术家完成
之前我们使用$history来记录历史上下文信息,这种方式问题是上下文信息太过于庞大,现在我们使用向量化的方式:TextMemorySkill,这个skill提供给我们call()方法来调用,并且每次调用都会记住上一次调用的上下文信息
简单来说:一直call()就行了!
async def setup_chat_with_memory(
kernel: sk.Kernel,
) -> Tuple[sk.SKFunctionBase, sk.SKContext]:
sk_prompt = """
聊天机器人可以与你就任何话题进行对话,如果某个问题没有答案,你可以直接回答“我不知道”
这里有一些之前我们对话的信息,是关于我的信息的,请参阅:
- {{$fact1}} {{recall $fact1}}
- {{$fact2}} {{recall $fact2}}
- {{$fact3}} {{recall $fact3}}
- {{$fact4}} {{recall $fact4}}
- {{$fact5}} {{recall $fact5}}
Chat:
{{$chat_history}}
User: {{$user_input}}
ChatBot: """.strip()
chat_func = kernel.create_semantic_function(sk_prompt, max_tokens=1000, temperature=0.8)
context = kernel.create_new_context()
context["fact1"] = "我叫什么"
context["fact2"] = "我住哪里?"
context["fact3"] = "我家来自哪里?"
context["fact4"] = "我去过哪里?"
context["fact5"] = "我曾经做过什么?"
context[sk.core_skills.TextMemorySkill.COLLECTION_PARAM] = "aboutMe"
context[sk.core_skills.TextMemorySkill.RELEVANCE_PARAM] = "0.8"
#这里的RELEVANCE_PARAM参数表示记忆相关度达到多少时就可以作为答案返回
context["chat_history"] = ""
return chat_func, context这里的RELEVANCE_PARAM参数表示记忆相关度达到多少时就可以作为答案返回
定义单轮对话方法:
async def chat(kernel: sk.Kernel, chat_func: sk.SKFunctionBase, context: sk.SKContext) -> bool:
try:
user_input = input("User:> ")
context["user_input"] = user_input
print(f"用户:> {user_input}")
except KeyboardInterrupt:
print("\n\nExiting chat...")
return False
except EOFError:
print("\n\nExiting chat...")
return False
if user_input == "exit":
print("\n\nExiting chat...")
return False
answer = await kernel.run_async(chat_func, input_vars=context.variables)
context["chat_history"] += f"\nUser:> {user_input}\nChatBot:> {answer}\n"
print(f"AI:> {answer}")
return True开始重新对话:
print("填充记忆中...")
await populate_memory(kernel)
print("询问问题中... (manually)")
await search_memory_examples(kernel)
print("正在更新记忆 (with memory!)")
chat_func, context = await setup_chat_with_memory(kernel)
print("开始对话! (type 'exit' to exit):\n")
chatting = True
while chatting:
chatting = await chat(kernel, chat_func, context)执行,这样就启动了个无线轮对话的服务,命令输入会在vscode的顶上弹出来,输入你的问题即可:
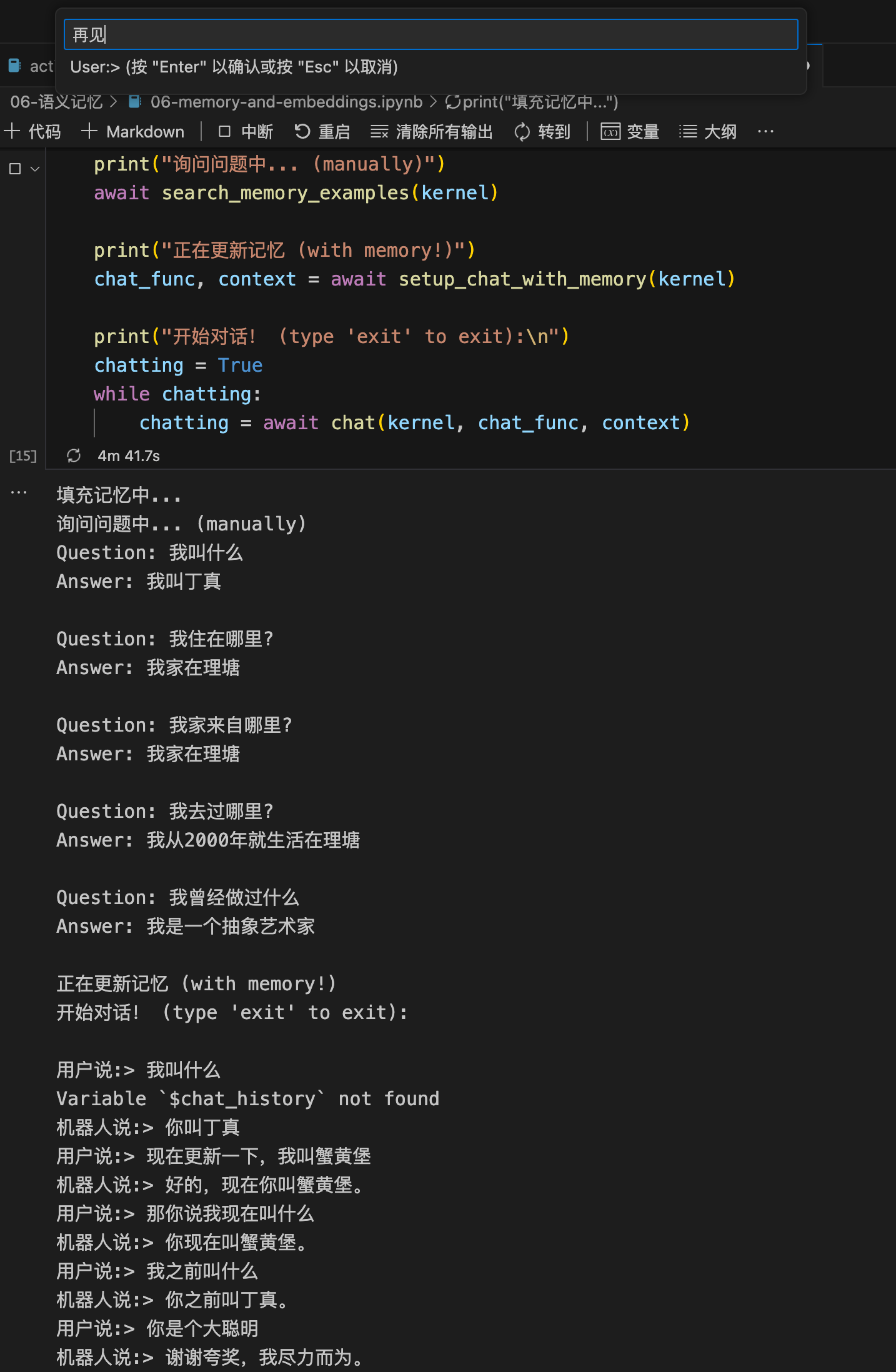
需要退出的话输入exit回车
2,如何导入外部文件资源作为LLM的记忆
这里演示如何通过文件url导入一些文件到memory,首先创建一个github_files字典来存储文件url和描述的映射:
github_files = {}
github_files[
"https://github.com/microsoft/semantic-kernel/blob/main/README.md"
] = "README: Installation, getting started, and how to contribute"
github_files[
"https://github.com/microsoft/semantic-kernel/blob/main/dotnet/notebooks/02-running-prompts-from-file.ipynb"
] = "Jupyter notebook describing how to pass prompts from a file to a semantic skill or function"
github_files[
"https://github.com/microsoft/semantic-kernel/blob/main/dotnet/notebooks/00-getting-started.ipynb"
] = "Jupyter notebook describing how to get started with the Semantic Kernel"
github_files[
"https://github.com/microsoft/semantic-kernel/tree/main/samples/skills/ChatSkill/ChatGPT"
] = "Sample demonstrating how to create a chat skill interfacing with ChatGPT"
github_files[
"https://github.com/microsoft/semantic-kernel/blob/main/dotnet/src/SemanticKernel/Memory/Volatile/VolatileMemoryStore.cs"
] = "C# class that defines a volatile embedding store"然后使用SaveReferenceAsync方法添加文件到memory:
memory_collection_name = "SKGitHub"
print("正在导入一些来自于github的文件到记忆内存中去...")
i = 0
for entry, value in github_files.items():
await kernel.memory.save_reference_async(
collection=memory_collection_name,
description=value,
text=value,
external_id=entry,
external_source_name="GitHub",
)
i += 1
print(" URL {} saved".format(i))
# #输出:
# 正在导入一些来自于github的文件到记忆内存中去...
# URL 1 saved
# URL 2 saved
# URL 3 saved
# URL 4 saved
# URL 5 saved导入记忆完成,开始提问:
ask = "我喜欢jupyter notebook,我如何开始使用这个工具?"
print("===========================\n" + "提问: " + ask + "\n")
memories = await kernel.memory.search_async(memory_collection_name, ask, limit=5, min_relevance_score=0.77)
i = 0
for memory in memories:
i += 1
print(f"结果 {i}:")
print(" URL: : " + memory.id)
print(" Title : " + memory.description)
print(" Relevance: " + str(memory.relevance))
print()
# 输出:
# ===========================
# 提问: 我喜欢jupyter notebook,我应该如何开始使用这个工具?
# 结果 1:
# URL: : https://github.com/microsoft/semantic-kernel/blob/main/dotnet/notebooks/00-getting-started.ipynb
# Title : Jupyter notebook describing how to get started with the Semantic Kernel
# 结果相关度: 0.814743408933172
# 结果 2:
# URL: : https://github.com/microsoft/semantic-kernel/blob/main/dotnet/notebooks/02-running-prompts-from-file.ipynb
# Title : Jupyter notebook describing how to pass prompts from a file to a semantic skill or function
# 结果相关度: 0.7766737339058303
# 结果 3:
# URL: : https://github.com/microsoft/semantic-kernel/blob/main/README.md
# Title : README: Installation, getting started, and how to contribute
# 结果相关度: 0.7725141770020837这种导入外部资源作为LLM本地记忆的手段非常有用,可以很快地使LLM成为某个领域的专家
3,导入Azure数据库作为LLM的知识库记忆
下面还演示了如何连接Azure数据库作为LLM的知识库:
importAzure=False
if importAzure:
from semantic_kernel.connectors.memory.azure_cognitive_search import (
AzureCognitiveSearchMemoryStore,
)
azure_ai_search_api_key, azure_ai_search_url = sk.azure_aisearch_settings_from_dot_env()
#记得配置.env文件的Azure数据库
# text-embedding-ada-002 uses a 1536-dimensional embedding vector
kernel.register_memory_store(
memory_store=AzureCognitiveSearchMemoryStore(
vector_size=1536,
search_endpoint=azure_ai_search_url,
admin_key=azure_ai_search_api_key,
)
)
await populate_memory(kernel)执行后,数据库会创建一个aboutme的index
然后搜索:
await search_memory_examples(kernel)4,导入pgsql数据库作为LLM的知识库记忆
TODO…
后面章节专门写下这个
六,使用Hugging Face进行skill开发
1,HF介绍
简单来说HF就是机器学习界的github,目前已经共享了超100,000个预训练模型,10,000个数据集,在这上面你无需详细搞懂他们的原理,就可以直接使用这些科研界最先进的模型。目前HF上面还是英文的数据集和模型数量远远高于其他语言
SK支持从Hugging Face下载可以执行以下任务的模型:文本生成、文本到文本生成、摘要生成和句子相似度计算。您可以在https://huggingface.co/models上按任务搜索模型。
2,配置环境
写在最前面:又碰到个大坑,花了半天时间才搞定
由于换了三次python版本,最终固定在了python3.9.6
但是macos是预装一个python解释器的,在/usr/bin/python3目录下,而且命令行默认使用这个解释器,当用户自己从官网安装其他版本python后,使用vscode等ide软件需要及时修改python解释器路径,如果还使用了jupyter这样的笔记软件,也要注意设置对python解释器,否则会发生pip包下载到解释器a的路径下,但是实际使用的是解释器b,死活导入不了包,😤
如果需要确定vscode的python解释器与jupyter解释器位置是否一致,可以使用以下代码,分别建立一个ipynb和py文件执行,看下输出的Executable Location是否一致:
import flask print(flask.__version__) import sys import platform # Python版本 print("Python Version:", sys.version) # Python解释器的版本信息 print("Version Info:", sys.version_info) # Python解释器的安装位置 print("Executable Location:", sys.executable)
安装基本包
# 链接HF上其他的模型需要下面的包:# 注:下面的包安装在python3.12环境下失败,在python3.9.6 base 环境下失败# 解决:使用conda新建一个基于python3.9.6的虚拟环境,内核kernel选择这个新建的虚拟环境,然后执行下面的安装包!python -m pip install torch==2.0.0!python -m pip install transformers==4.28.1!python -m pip install sentence-transformers==2.2.2#新环境别忘了安装sk的包哦!python -m pip install semantic-kernel==0.4.5.dev0
导入包试下:
import semantic_kernel as sk
import semantic_kernel.connectors.ai.hugging_face as sk_hf如果没问题就说明环境ok了
3,使用
首先,我们将创建一个内核并添加文本完成和嵌入服务。
对于文本补全,我们选择 GPT2。这是一个文本生成模型。 text2text- Generation
(注意:文本生成将在输出中重复输入, 不会。)对于嵌入,我们使用句子转换器/all-MiniLM-L6-v2。为此模型生成的向量长度为 384(相比之下,OpenAI ADA 的长度为 1536)。首次运行时,以下步骤可能需要几分钟时间,因为模型将下载下来,耐心等待一下:
import semantic_kernel as sk
import semantic_kernel.connectors.ai.hugging_face as sk_hf
kernel = sk.Kernel()
# Configure LLM service
kernel.add_text_completion_service(
service_id="gpt2", service=sk_hf.HuggingFaceTextCompletion(ai_model_id="gpt2", task="text-generation")
)
kernel.add_text_embedding_generation_service(
service_id="sentence-transformers/all-MiniLM-L6-v2",
service=sk_hf.HuggingFaceTextEmbedding(ai_model_id="sentence-transformers/all-MiniLM-L6-v2"),
)
kernel.register_memory_store(memory_store=sk.memory.VolatileMemoryStore())
kernel.import_skill(sk.core_skills.TextMemorySkill())写入记忆,增加技能:
await kernel.memory.save_information_async(collection="animal_facts", id="info1", text="水是有剧毒的")
await kernel.memory.save_information_async(collection="animal_facts", id="info2", text="蚊子是可爱的")
await kernel.memory.save_information_async(collection="animal_facts", id="info3", text="猪猪是凶恶的")
await kernel.memory.save_information_async(collection="animal_facts", id="info4", text="先有鸡后有蛋")
await kernel.memory.save_information_async(collection="animal_facts", id="info5", text="动物不能喝水")
# Define semantic function using SK prompt template language
my_prompt = """我知道关于动物的以下事实: {{recall $query1}} {{recall $query2}} {{recall $query3}} and """
# Create the semantic function
my_function = kernel.create_semantic_function(prompt_template=my_prompt, max_tokens=45, temperature=0.7, top_p=0.5)看看结果:
context = kernel.create_new_context()
context[sk.core_skills.TextMemorySkill.COLLECTION_PARAM] = "animal_facts"
context[sk.core_skills.TextMemorySkill.RELEVANCE_PARAM] = "0.3"
context["query1"] = "水是有毒的吗?"
context["query2"] = "先有鸡还是先有蛋"
context["query3"] = "蚊子招人讨厌不"
output = await kernel.run_async(my_function, input_vars=context.variables)
output = str(output).strip()
query_result1 = await kernel.memory.search_async(
collection="animal_facts", query=context["query1"], limit=1, min_relevance_score=0.3
)
query_result2 = await kernel.memory.search_async(
collection="animal_facts", query=context["query2"], limit=1, min_relevance_score=0.3
)
query_result3 = await kernel.memory.search_async(
collection="animal_facts", query=context["query3"], limit=1, min_relevance_score=0.3
)
print(f"gpt2 完成: '{output}'")报错:
gpt2 完成: ‘Error: (‘Hugging Face completion failed’, TypeError(“__call__() missing 1 required positional argument: ‘text_inputs'”), None)’
缺少了text_inputs这个参数
TODO:暂未解决
七,一个请求获取多个生成的结果
SK支持对于一个模型让LLM给出多个结果,实现这一目标通常涉及以下几个步骤:
- 配置请求参数:设置请求以便模型返回多个回答。这可能包括调整如返回数量number_of_responses、创造性(通常称为“temperature”)或多样性参数(如“top_k”或“top_p”)等设置。
- 发送请求:将配置好的请求发送给模型。这通常通过 API 调用或使用特定库(如 OpenAI GPT)实现。
- 分析结果:评估和分析模型返回的多个回答,寻找模式、一致性或差异性。这可以帮助您理解模型的表现和可能的改进方向。
- 迭代优化:基于收集到的反馈,调整提示或配置参数,重复实验,以找到最优的提示策略和参数设置。
这种方法特别适用于研究人员和开发人员,他们需要深入理解模型的行为并优化其性能。通过对比不同的结果,可以更好地理解模型的回答是如何受到各种因素的影响,进而提高使用大型语言模型的有效性和准确性
#services.py放在同本python文件同级目录下
from services import Service
# Select a service to use for this notebook (available services: OpenAI, AzureOpenAI, HuggingFace)
selectedService = Service.OpenAI
import semantic_kernel as sk
from semantic_kernel.connectors.ai.open_ai.request_settings.open_ai_request_settings import (
OpenAITextRequestSettings,
OpenAIChatRequestSettings,
)
from semantic_kernel.connectors.ai.open_ai import (
OpenAITextCompletion,
OpenAIChatCompletion,
)
kernel = sk.Kernel()
api_key, org_id = sk.openai_settings_from_dot_env()
oai_text_service = OpenAITextCompletion(ai_model_id="gpt-3.5-turbo-instruct", api_key=api_key, org_id=org_id)
# 吐槽:官方文档写的太草率了,gpt3.5都能写成gpt35
# oai_text_service = OpenAITextCompletion(ai_model_id="gpt-35-turbo-instruct", api_key=api_key, org_id=org_id)
oai_chat_service = OpenAIChatCompletion(ai_model_id="gpt-3.5-turbo", api_key=api_key, org_id=org_id)
- 配置参数:
oai_text_request_settings = OpenAITextRequestSettings(
extension_data={
"max_tokens": 1000,
"temperature": 0.7,
"top_p": 1,
"frequency_penalty": 0.5,
"presence_penalty": 0.5,
"number_of_responses": 3,#结果数,3表示给出三个结果
}
)发送请求提问:
prompt = "为什么大部分男生喜欢打游戏?"
results = await oai_text_service.complete_async(prompt=prompt, settings=oai_text_request_settings)
i = 1
for result in results:
print(f"结果 {i}: {result}")
i += 1
# 输出了三个结果流式传输多结果示例,注意这个不支持HF的模型:
import os
from IPython.display import clear_output
import time
# Determine the clear command based on OS
clear_command = "cls" if os.name == "nt" else "clear"
prompt = "为什么大部分男生喜欢打游戏?"
stream = oai_text_service.complete_stream_async(prompt=prompt, settings=oai_text_request_settings)
number_of_responses = oai_text_request_settings.number_of_responses
texts = [""] * number_of_responses
last_clear_time = time.time()
clear_interval = 0.5 # seconds
# 注意:在显示输出时有一些怪癖,有时候输出会快速闪烁然后消失。
# 这可能受到一些特定于 Jupyter 笔记本和异步处理的因素的影响。
# 下面的代码尝试缓冲结果,以避免输出在屏幕上快速闪烁/消失。
async for results in stream:
current_time = time.time()
# Update texts with new results
for idx, result in enumerate(results):
if idx < number_of_responses:
texts[idx] += result
# Clear and display output at intervals
if current_time - last_clear_time > clear_interval:
clear_output(wait=True)
for idx, text in enumerate(texts):
print(f"结果 {idx + 1}: {text}")
last_clear_time = current_time
print("----------------------------------------")总结:通过一个请求获取多个生成的结果,这对于进行实验非常有用,特别是当想要评估针对特定大型语言模型的提示的健壮性和配置参数时
八,连接pgsql数据库作为LLM的知识库记忆
mac忘记root密码解决方案:https://blog.csdn.net/gnail_oug/article/details/79846474
1,环境安装
注:这部分坑很大,建议直接看建议先看完环境安装部分后,再动手安装
- 安装本地pgsql
官网下载本地postgressql数据库,安装:
下载15.5版本的即可:
安装完成后,创建用户,创建一个数据库叫做db_sk
- 安装vector插件
cd /tmp
git clone --branch v0.5.1 https://github.com/pgvector/pgvector.git
cd pgvector
make
make install # may need sudo实测不行,尝试下面安装命令:
首先查看插件安装目录:
CREATE EXTENSION 查看插件目录;
#不用替换,直接执行输出:
ERROR: Could not open extension control file
"/Library/PostgreSQL/15/share/postgresql/extension/查看插件目录.control": No such file or directory.extension "查看插件目录" is not available这里得到的/Library/PostgreSQL/15/share/postgresql/extension/就是pgsql数据库加载插件的目录
然后
make install DESTDIR= /Library/PostgreSQL/15/share/postgresql/extension/还是不行,谁来救救鼠鼠
破案了,是因为电脑原本就有个pgsql14,然后又手动装了个pgsql15。结果make安装在了pgsql14的目录,命令行pg–version输出的是pgsql14,命令行打开pgsql导入插件又在pgsql15的插件目录查找,pgadmin4安装插件在pgsql15的目录查找,全tm乱了
解决:卸载干净pgsql,重新安装
结果:很奇怪,重新安装后还是显示命令行pg14,server是15,使用gpt给的方法可以安装插件了:
- 安装 PostgreSQL 15
首先,使用 Homebrew 安装 PostgreSQL 15。这通常不会覆盖或删除旧版本,因为 Homebrew 会将它们视为不同的实例。
brew install postgresql@15这将安装 PostgreSQL 15 的最新版本。
- 链接 PostgreSQL 15
如果您想将 PostgreSQL 15 设置为默认版本,您可能需要更改一些链接。但在这之前,请确保您了解这会改变默认的 psql 命令指向的版本。
brew link --overwrite postgresql@15- 启动 PostgreSQL 15
使用 Homebrew 服务启动 PostgreSQL 15:
brew services start postgresql@15确认下版本对不对:
psql --version输出15.5就对了。接着把原本这几个目录里面的vector删干净:
rm -rf /usr/local/Cellar/postgresql@14/14.10_1/share/postgresql@14/extension/vector*
rm -rf /Library/PostgreSQL/15/share/postgresql/extension/
rm -rf /usr/local/Cellar/postgresql@14/14.10_1/lib/postgresql@14/vector*
rm -rf /Library/PostgreSQL/15/lib/postgresql删干净后,重新make:
make clean # 清理旧的编译文件
make # 编译扩展
sudo make install # 安装扩展
确认下安装的位置:
find / -name vector.controlpc@JayMacBook-Pro pgvector % find / -name vector.control
find: /usr/sbin/authserver: Permission denied
/usr/local/Cellar/postgresql@15/15.5_3/share/postgresql@15/extension/vector.control
/usr/local/Cellar/pgvector/0.5.1_2/share/postgresql@14/extension/vector.control
find: /Library/Application Support/Apple/ParentalControls/Users: Permission deniedpostgres=# CREATE EXTENSION vector;
ERROR: extension "vector" is not available
描述: Could not open extension control file "/Library/PostgreSQL/15/share/postgresql/extension/vector.control": No such file or directory.
提示: The extension must first be installed on the system where PostgreSQL is running.服了,还是不一致,可以看到make的目录根本就和pgsql查找插件的目录不一致,直接手动复制把
sudo cp /usr/local/Cellar/postgresql@15/15.5_3/share/postgresql@15/extension/vector* /Library/PostgreSQL/15/share/postgresql/extension/
sudo cp /usr/local/Cellar/postgresql@15/15.5_3/lib/postgresql/vector* /Library/PostgreSQL/15/lib/postgresql终于成功了!!!
postgres=# CREATE EXTENSION vector;
CREATE EXTENSION
postgres=# 太不容易了,这个插件安装了整整一天,踩了无数的坑
再次确认下已经导入:
SELECT * FROM pg_extension WHERE extname = 'vector';
没问题
查看下vector的版本:

没问题了
//后面删除很多很多报错记录。。。都是血泪经验
2,SK连接pgsql数据库写入文本记忆并查询
配置.env文件:
#新建数据库db_sk即可
# OPENAI_API_KEY="sk-xxx"
#gpt3.5
OPENAI_API_KEY="sk-xxx"
OPENAI_ORG_ID=""
AZURE_OPENAI_DEPLOYMENT_NAME=""
AZURE_OPENAI_ENDPOINT=""
AZURE_OPENAI_API_KEY=""
AZURE_AISEARCH_API_KEY=""
AZURE_AISEARCH_URL=""
#需要配置线这个pg数据库的链接string
POSTGRES_CONNECTION_STRING="host=localhost port=5432 dbname=db_sk connect_timeout=10 user=postgres password=320320"
#postgresql://postgresql:leboxj@localhost:5432from typing import Tuple
import semantic_kernel_main.python.semantic_kernel as sk
from semantic_kernel_main.python.semantic_kernel.connectors.ai.open_ai import (
OpenAIChatCompletion,
OpenAITextEmbedding,
)
kernel = sk.Kernel()
api_key, org_id = sk.openai_settings_from_dot_env()
oai_chat_service = OpenAIChatCompletion(ai_model_id="gpt-3.5-turbo", api_key=api_key, org_id=org_id)
oai_text_embedding = OpenAITextEmbedding(ai_model_id="text-embedding-ada-002", api_key=api_key, org_id=org_id)
kernel.add_chat_service("chat-gpt", oai_chat_service)
kernel.add_text_embedding_generation_service("ada", oai_text_embedding)
kernel.register_memory_store(memory_store=sk.memory.VolatileMemoryStore())
kernel.import_skill(sk.core_skills.TextMemorySkill())配置数据库,写入记忆:
async def populate_memory(kernel: sk.Kernel) -> None:
# 编写填充/写入记忆的函数
await kernel.memory.save_information_async(collection="aboutMe", id="info1", text="我叫丁真")
await kernel.memory.save_information_async(collection="aboutMe", id="info2", text="我是一个抽象艺术家")
await kernel.memory.save_information_async(collection="aboutMe", id="info3", text="我从2000年就生活在理塘")
await kernel.memory.save_information_async(collection="aboutMe", id="info4", text="从2015年起我每天抽电子烟",)
await kernel.memory.save_information_async(collection="aboutMe", id="info5", text="我家在理塘")
from semantic_kernel_main.python.semantic_kernel.connectors.memory.postgres import (
PostgresMemoryStore,
)
postgres_connection_string = sk.postgres_settings_from_dot_env()
#记得配置.pgsql
# text-embedding-ada-002 uses a 1536-dimensional embedding vector
kernel.register_memory_store(
memory_store=PostgresMemoryStore(
connection_string=postgres_connection_string,
min_pool=5,
max_pool=20,
schema="public",
default_dimensionality=50,
)
)
然后调用populate_memory()将数据存储到数据库:
await populate_memory(kernel)这里可能会报错:
---------------------------------------------------------------------------
DataException Traceback (most recent call last)
Cell In[6], line 1----> 1 await populate_memory(kernel)
Cell In[5], line 31 async def populate_memory(kernel: sk.Kernel) -> None:
2 # 编写填充/写入记忆的函数
----> 3 await kernel.memory.save_information_async(collection="aboutMe", id="info1", text="我叫丁真")
4 await kernel.memory.save_information_async(collection="aboutMe", id="info2", text="我是一个抽象艺术家")
5 await kernel.memory.save_information_async(collection="aboutMe", id="info3", text="我从2000年就生活在理塘")
File /Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/semantic_kernel/memory/semantic_text_memory.py:67, in SemanticTextMemory.save_information_async(self, collection, text, id, description, additional_metadata)
58 embedding = (await self._embeddings_generator.generate_embeddings_async([text]))[0]
59 data = MemoryRecord.local_record(
60 id=id,
61 text=text,
(...)
64 embedding=embedding,
65 )
---> 67 await self._storage.upsert_async(collection_name=collection, record=data)
File /Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/semantic_kernel/connectors/memory/postgres/postgres_memory_store.py:155, in PostgresMemoryStore.upsert_async(self, collection_name, record)
153 if not await self.__does_collection_exist_async(cur, collection_name):
154 raise Exception(f"Collection '{collection_name}' does not exist")
...
731except e._NO_TRACEBACK as ex:
--> 732 raise ex.with_traceback(None)
733return self
DataException: expected 50 dimensions, not 1536这是因为text-embedding-ada-002 uses a 1536-dimensional embedding vector
解决方案:
将上面的default_dimensionality参数修改为1536,修改完后,一定要记得:删除数据库生成的aboutMe的表,不然会报同样的错,因为这个表已经生成了,对应的列需要50维度的数据,但是提供的1536维度数据,所以不断报错,把之前的表删除即可,这个问题排查了好久,,,
然后开始提问:
result = await kernel.memory.search_async("aboutMe", "你每天都会干什么")
print(result[0].text)
#我每天抽电子烟没问题,写入新的记忆:
async def populate_memory2(kernel: sk.Kernel) -> None:
# 编写填充/写入记忆的函数
await kernel.memory.save_information_async(collection="aboutMe2", id="info1", text="我叫李四")
await kernel.memory.save_information_async(collection="aboutMe2", id="info2", text="我是一个犯罪艺术家")
await kernel.memory.save_information_async(collection="aboutMe2", id="info3", text="我每天打罗翔老师")
await kernel.memory.save_information_async(collection="aboutMe2", id="info4", text="我住在理塘",)
await kernel.memory.save_information_async(collection="aboutMe2", id="info5", text="我是广东人")
#别忘了写入
await populate_memory2(kernel)result = await kernel.memory.search_async("aboutMe2", "你现在每天都会干什么")
print(result[0].text)
#我现在每天打罗翔老师
result = await kernel.memory.search_async("aboutMe2", "你之前叫什么")
print(result[0].text)
#我叫李四没问题!
这里说明下:
kernel.register_memory_store(
memory_store=PostgresMemoryStore(
connection_string=postgres_connection_string,
min_pool=5,
max_pool=20,
schema="public",
default_dimensionality=1536,
)
)这个函数不光是链接了pgsql数据库,还顺便读取了数据库中的数据,所以可以尝试运行下面的代码:
from typing import Tuple
import semantic_kernel_main.python.semantic_kernel as sk
from semantic_kernel_main.python.semantic_kernel.connectors.ai.open_ai import (
OpenAIChatCompletion,
OpenAITextEmbedding,
)
kernel = sk.Kernel()
api_key, org_id = sk.openai_settings_from_dot_env()
oai_chat_service = OpenAIChatCompletion(ai_model_id="gpt-3.5-turbo", api_key=api_key, org_id=org_id)
oai_text_embedding = OpenAITextEmbedding(ai_model_id="text-embedding-ada-002", api_key=api_key, org_id=org_id)
kernel.add_chat_service("chat-gpt", oai_chat_service)
kernel.add_text_embedding_generation_service("ada", oai_text_embedding)
kernel.register_memory_store(memory_store=sk.memory.VolatileMemoryStore())
kernel.import_skill(sk.core_skills.TextMemorySkill())
from semantic_kernel_main.python.semantic_kernel.connectors.memory.postgres import (
PostgresMemoryStore,
)
postgres_connection_string = sk.postgres_settings_from_dot_env()
#记得配置.pgsql
# text-embedding-ada-002 uses a 1536-dimensional embedding vector
kernel.register_memory_store(
memory_store=PostgresMemoryStore(
connection_string=postgres_connection_string,
min_pool=5,
max_pool=20,
schema="public",
default_dimensionality=1536,
)
)
result = await kernel.memory.search_async("aboutMe2", "你现在每天都会干什么")
print(result[0].text)
result = await kernel.memory.search_async("aboutMe2", "你之前叫什么")
print(result[0].text)还是能得到之前写入的记忆:
我每天打罗翔老师
我叫李四这样就实现了记忆的数据库存储与读取
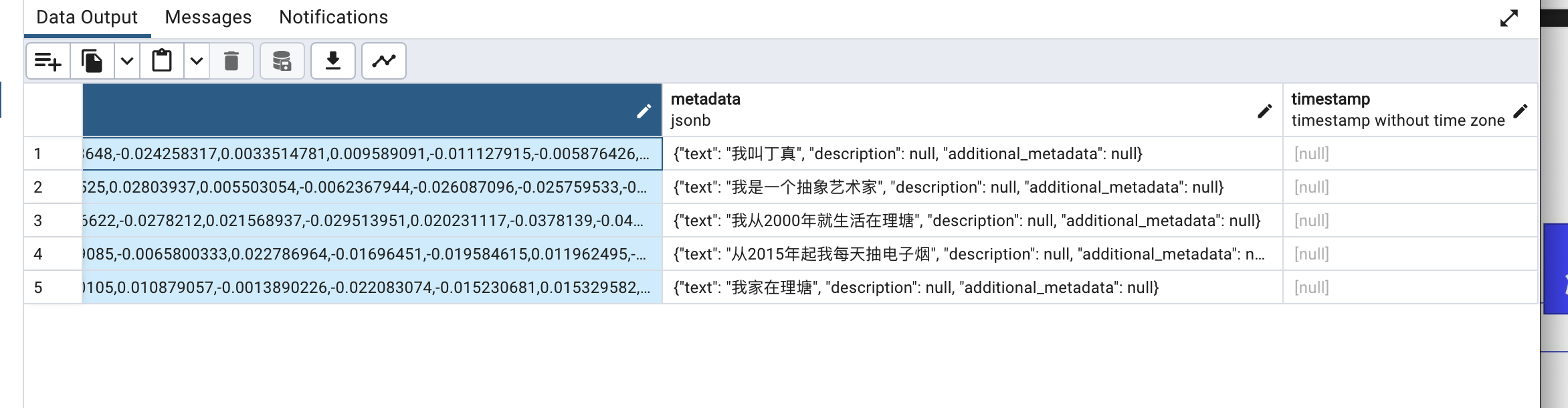
打开数据库,可以看到创建了两个表,写入为嵌入vector数据:
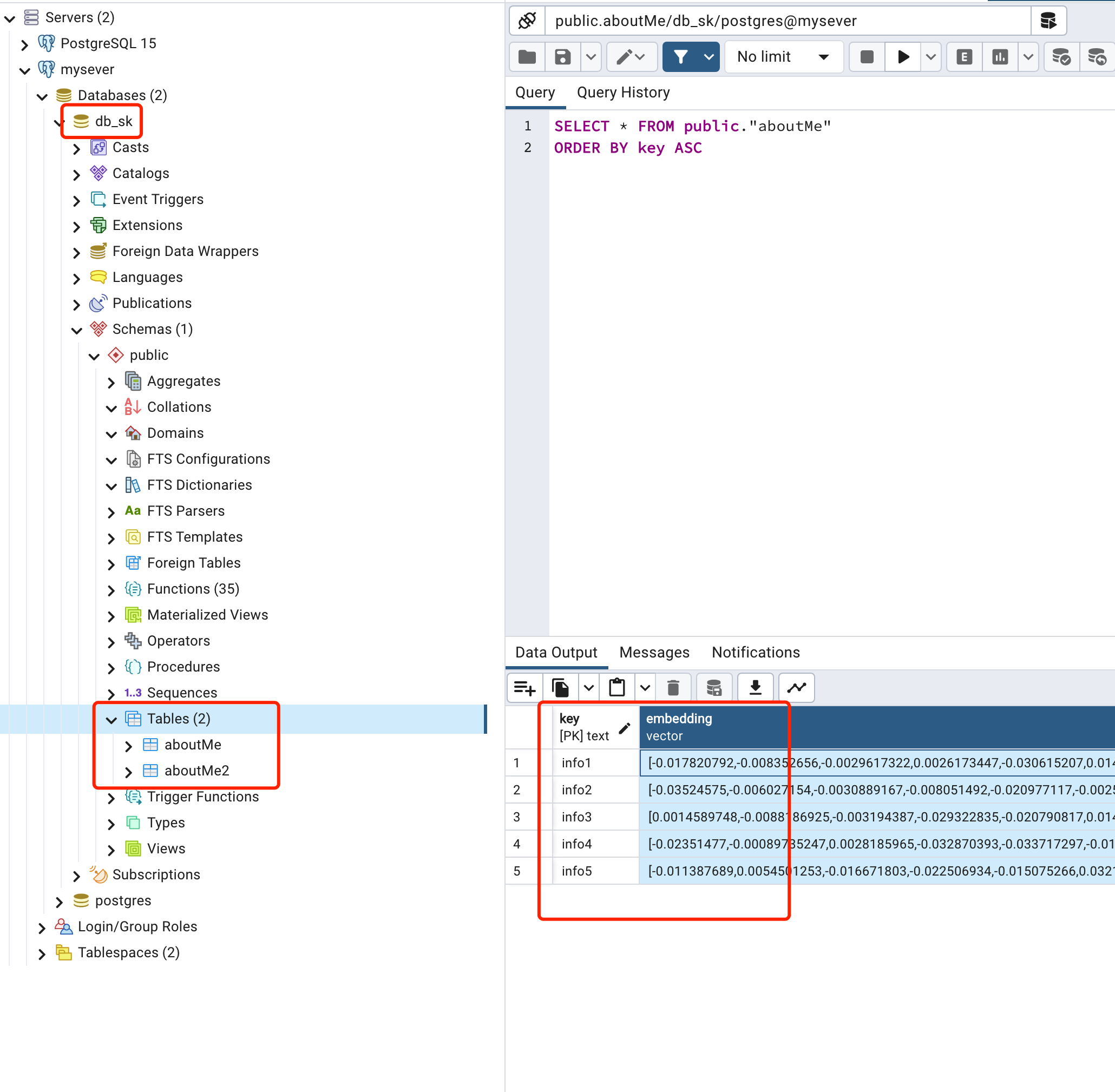
其中embedding列非常长,后面还有metadata,存储的是原始的文本数据